
Azure DevOps Ansible Pipeline; Boosting Efficiency with Caching

Back in May 2020 I published what would be one of the more popular posts on this blog Azure DevOps Ansible Pipeline, it covered the Azure DevOps pipeline I had settled upon for running my Ansible playbooks which built and interacted with workloads running in Microsoft Azure.
Fast forward four years, I updated the pipeline for Chapter 15 of the second edition of Learn Ansible; this version of the pipeline, which is covered in detail in the book, can be found in the repo linked below;

After the book was published, it occurred to me that something was missing from the pipeline, and that is caching !!!
The Learn Ansible Pipeline
For those of you who haven’t read the second edition of Learn Ansible, this updated Azure DevOps pipeline automates the secure deployment of Ansible playbooks by first running a KICS (Keeping Infrastructure as Code Secure) scan to identify potential security vulnerabilities in the infrastructure code. It then parses the scan results to determine whether it’s safe to proceed with the deployment, setting a flag to either continue or halt the pipeline based on the severity of any issues found.
If the security checks pass, the pipeline sets up the necessary Azure credentials, installs the required Ansible collections and dependencies, and finally executes the Ansible playbook, capturing and publishing the deployment output for easy review.
The only downside was that it could take quite a while to execute. To circumvent this for another project I am working on, I have added a small level of caching to the pipeline code.
Introducing Caching
All of the work to introduce caching happens in the Run Ansible stage of the pipeline; the first of the changes happens just after the task, which sets up the Azure CLI and exposes the service principles credentials as environment variables.
Before we get there, though, a few additional variables are introduced at the top of the file. These are …
- name: PATH_COLLECTION value: /home/vsts/.ansible/collections/ansible_collections/azure/azcollection- name: PATH_VENV value: $(Pipeline.Workspace)/venv- name: CACHE_VERSION value: v001- name: REQUIREMENTS_FILE_NAME value: requirements.txtWhile they mainly deal with paths, the last one is important as the Azure Collection maintainers at Microsoft kindly changed the name of the requirements file we are using to install the Python modules we need for the pipeline to work. This changed the name of the requirements file, which broke all the builds I had that used it; thanks for that grrrrrrr 😠.
Also, as a bonus, should you ever need to update the cache, change the CACHE_VERSION variable, which will force a new cache to be created when the pipeline subsequently runs.
Set up the virtual environment.
This task configures a virtual environment; this is important as we will be taking a copy of the virtual environment for future runs of the pipelines:
- task: Bash@3 name: "setup_environment" displayName: "Setup Python Environment" inputs: targetType: "inline" script: | echo "##[group]Setup Python Virtual Environment" python3 -m venv $(PATH_VENV) source $(PATH_VENV)/bin/activate pip install --upgrade pip echo "##[endgroup]"The next task is as per the original pipeline, which grabs a copy of the private and public SSH keys and then copies them to the host running the Azure DevOps agent.
Check if there is an active cache
Next up, we have the Cache@2 task; with this task, we both check to see if there is already an active cache and if there isn’t, at the end of the pipeline run, a cache will be created will save us time and network bandwidth by caching files between pipeline runs.
- task: Cache@2 name: "cache_venv" displayName: "Cache virtual environment" inputs: key: 'venv$(CACHE_VERSION) | "$(Agent.OS)" | $(PATH_COLLECTION)/$(REQUIREMENTS_FILE_NAME)' path: $(PATH_VENV) cacheHitVar: CACHE_RESTOREDThe inputs needed for the task to run are;
- Key: The
keyinput is crucial for identifying the cache. It’s composed of:- A
CACHE_VERSIONvariable (allowing you to invalidate all caches by changing this version) - The operating system of the agent (
Agent.OS) - The path to the requirements file (
PATH_COLLECTION/REQUIREMENTS_FILE_NAME) This combination ensures that the cache is specific to the current environment and dependencies.
- A
- Path: The
pathinput specifies what should be cached, in this case, the virtual environment directory (PATH_VENV). - Cache Hit Variable: The
cacheHitVaris set toCACHE_RESTORED. This variable will be set to ‘true’ if the cache is successfully restored, allowing subsequent tasks to know whether they need to reinstall dependencies or can use the cached version.
Install the requirements if there is no active cache
This next task is responsible for installing dependencies when the cache isn’t available.
- task: Bash@3 name: "install_dependencies" displayName: "Install Dependencies" condition: ne(variables.CACHE_RESTORED, 'true') inputs: targetType: "inline" script: | echo "##[group]Install pip requirements" source $(PATH_VENV)/bin/activate pip install ansible[azure] ansible-galaxy collection install --force azure.azcollection pip install -r $(PATH_COLLECTION)/$(REQUIREMENTS_FILE_NAME) pip freeze > $(PATH_VENV)/$(REQUIREMENTS_FILE_NAME) echo "##[endgroup]"Here’s an explanation of what’s happening:
- Task Type: It’s using the
Bash@3task, which allows running Bash scripts in the pipeline. - Purpose: The task installs necessary dependencies, including Ansible and its Azure-related packages, as well as any other requirements specified in a requirements file.
- Condition: The
conditionfield specifies that this task only runs ifCACHE_RESTOREDis not ‘true’. This means it will skip the installation if the previous caching task successfully restored the virtual environment. - Script Content:
- It activates the virtual environment.
- Installs Ansible with Azure support using pip.
- Uses ansible-galaxy to install the Azure collection, forcing an update if it already exists.
- Installs additional requirements from a specified requirements file.
- Generates a new requirements file based on the current state of the virtual environment.
- Output Grouping: The
##[group]and##[endgroup]syntax is used to group the output in Azure DevOps, making the logs more readable.
This task ensures that all necessary dependencies are installed when the cache isn’t available or is outdated. By conditionally running this task, we are instructing the pipeline to use cached dependencies when possible, falling back to a fresh installation only when needed. This approach balances between speed (using cached dependencies) and reliability (ensuring up-to-date packages when necessary).
Run the Ansible Playbook.
This task is responsible for running the Ansible playbook and handling its output; there have been some changes to the task since the Learn Ansible version, these changes load the virtual environment and also confirm that the Azure modules are available:
- task: Bash@3 name: "ansible" displayName: "Run Ansible" env: AZURE_CLIENT_ID: $(ARM_CLIENT_ID) AZURE_SECRET: $(ARM_CLIENT_SECRET) AZURE_TENANT: $(ARM_TENANT_ID) AZURE_SUBSCRIPTION_ID: $(ARM_SUBSCRIPTION_ID) ANSIBLE_HOST_KEY_CHECKING: "False" inputs: targetType: "inline" script: | echo "##[group]Add SSH key" echo "$(SSH_PUBLIC_KEY)" > ~/.ssh/id_rsa.pub chmod 644 ~/.ssh/id_rsa.pub echo "##[endgroup]" echo "##[group]Verify Azure module installation" source $(PATH_VENV)/bin/activate python -c "import azure; print('Azure module is available')" echo "##[endgroup]" echo "##[group]Run the Ansible Playbook" ansible-playbook -i inv site.yml 2>&1 | tee $(System.DefaultWorkingDirectory)/ansible_output.log echo "##[endgroup]" echo "##[group]Create the markdown file for the Ansible Playbook Output" mkdir -p $(System.DefaultWorkingDirectory)/markdown echo "# Ansible Playbook Output" > $(System.DefaultWorkingDirectory)/markdown/summary.md echo "<details><summary>Click to expand</summary>" >> $(System.DefaultWorkingDirectory)/markdown/summary.md echo "" >> $(System.DefaultWorkingDirectory)/markdown/summary.md echo "\`\`\`" >> $(System.DefaultWorkingDirectory)/markdown/summary.md cat $(System.DefaultWorkingDirectory)/ansible_output.log >> $(System.DefaultWorkingDirectory)/markdown/summary.md echo "\`\`\`" >> $(System.DefaultWorkingDirectory)/markdown/summary.md echo "</details>" >> $(System.DefaultWorkingDirectory)/markdown/summary.md echo "##[endgroup]"Let’s take a deeper dive; as you can see, it uses the Bash@3 task to execute a series of bash commands. The task begins by setting up Azure-related environment variables for authentication and disables Ansible host key checking for non-interactive execution.
The script content is divided into several sections. First, it sets up an SSH key by adding a public key to the pipeline environment and setting appropriate permissions. Next, it verifies the Azure module’s availability by activating the virtual environment and running a Python command to import the Azure module.
The core of this task is executing the Ansible playbook. It runs the site.yml playbook using a specified inventory file (inv) and captures the output in both the console and a log file. This step likely configures or manages Azure resources as defined in the playbook.
Following the playbook execution, the task creates a markdown summary of the Ansible output. It generates a markdown file with an expandable section containing the full Ansible output within code blocks. This summary allows quick access to the Ansible output directly in the Azure DevOps UI, particularly useful for troubleshooting or auditing pipeline runs.
Throughout the script, the task uses ##[group] and ##[endgroup] commands to organize the pipeline logs into clear, collapsible sections. This improves readability in the Azure DevOps interface.
Seeing it in action
As you can see from the screens below, the first run took nearly 6 minutes; however, the second run took nearly half the time and was just under 3 minutes now that the cache is in place:
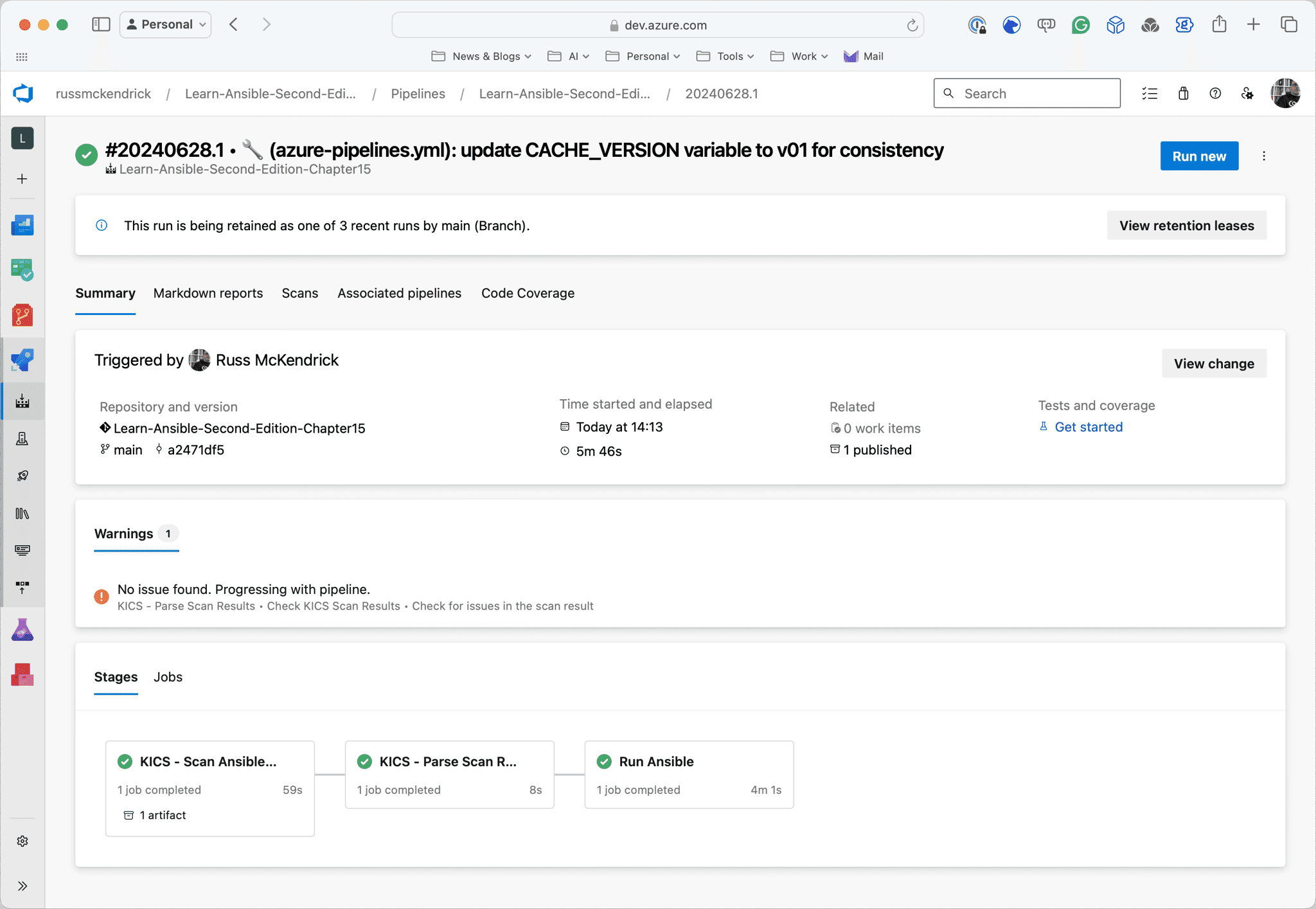
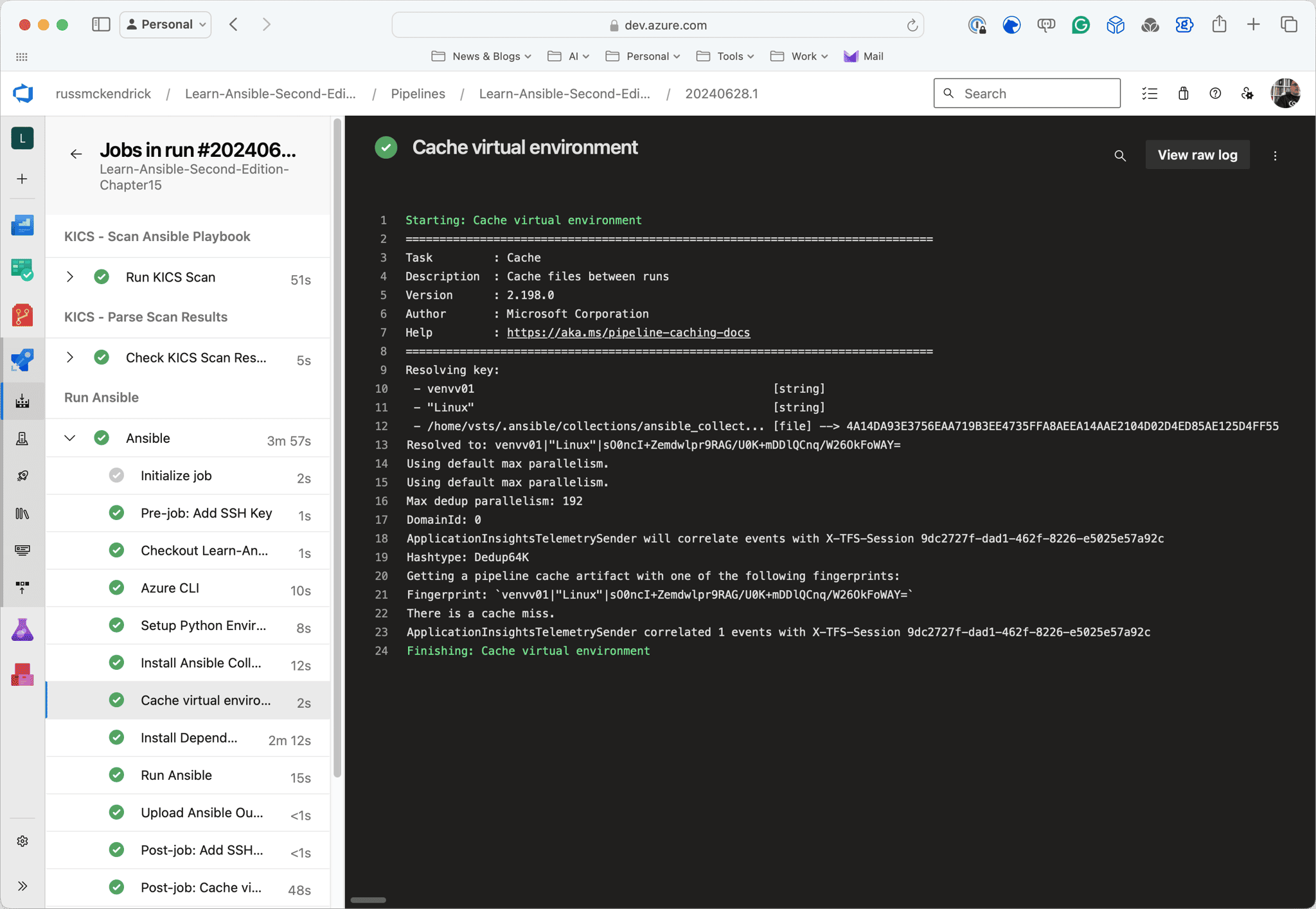
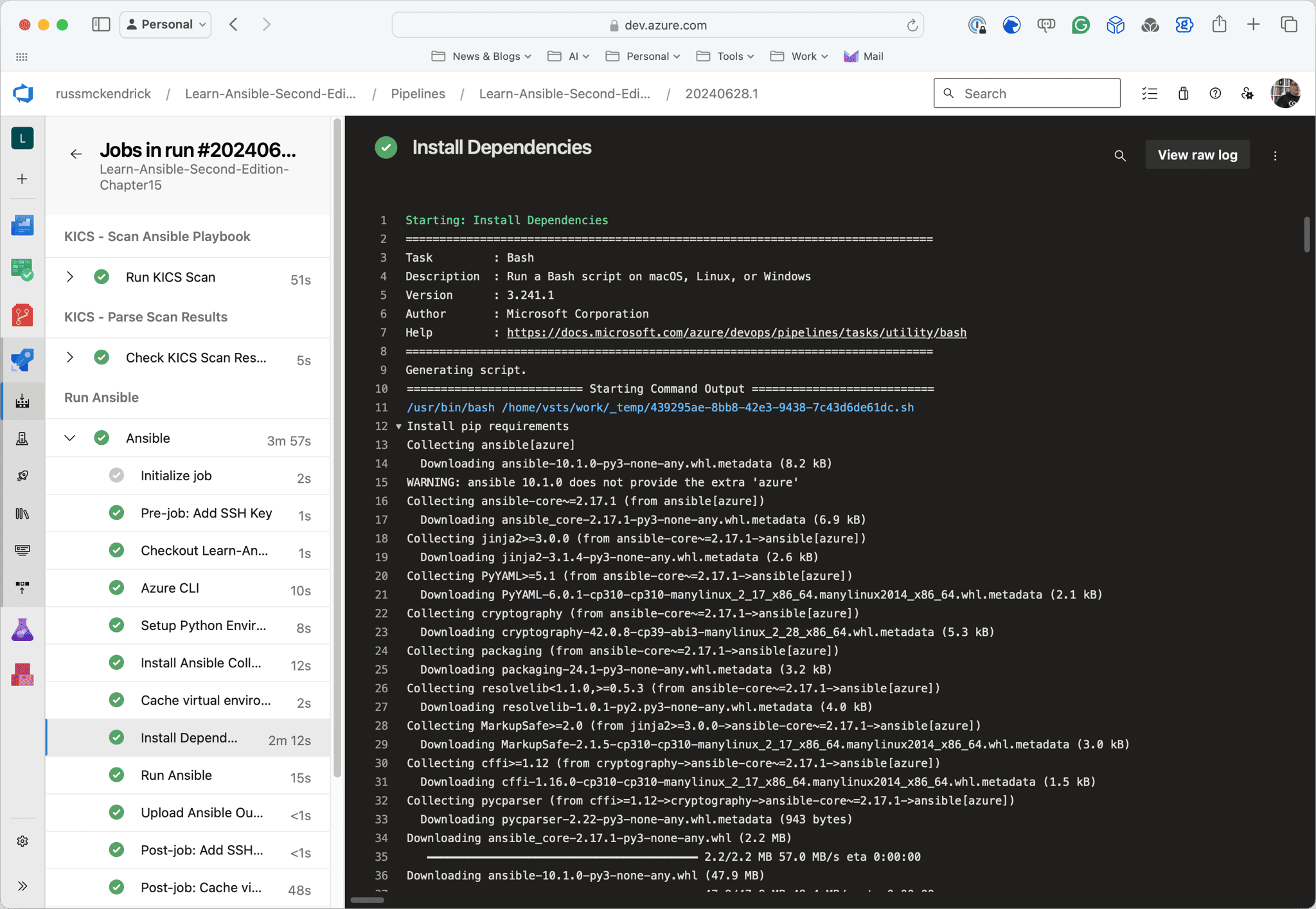
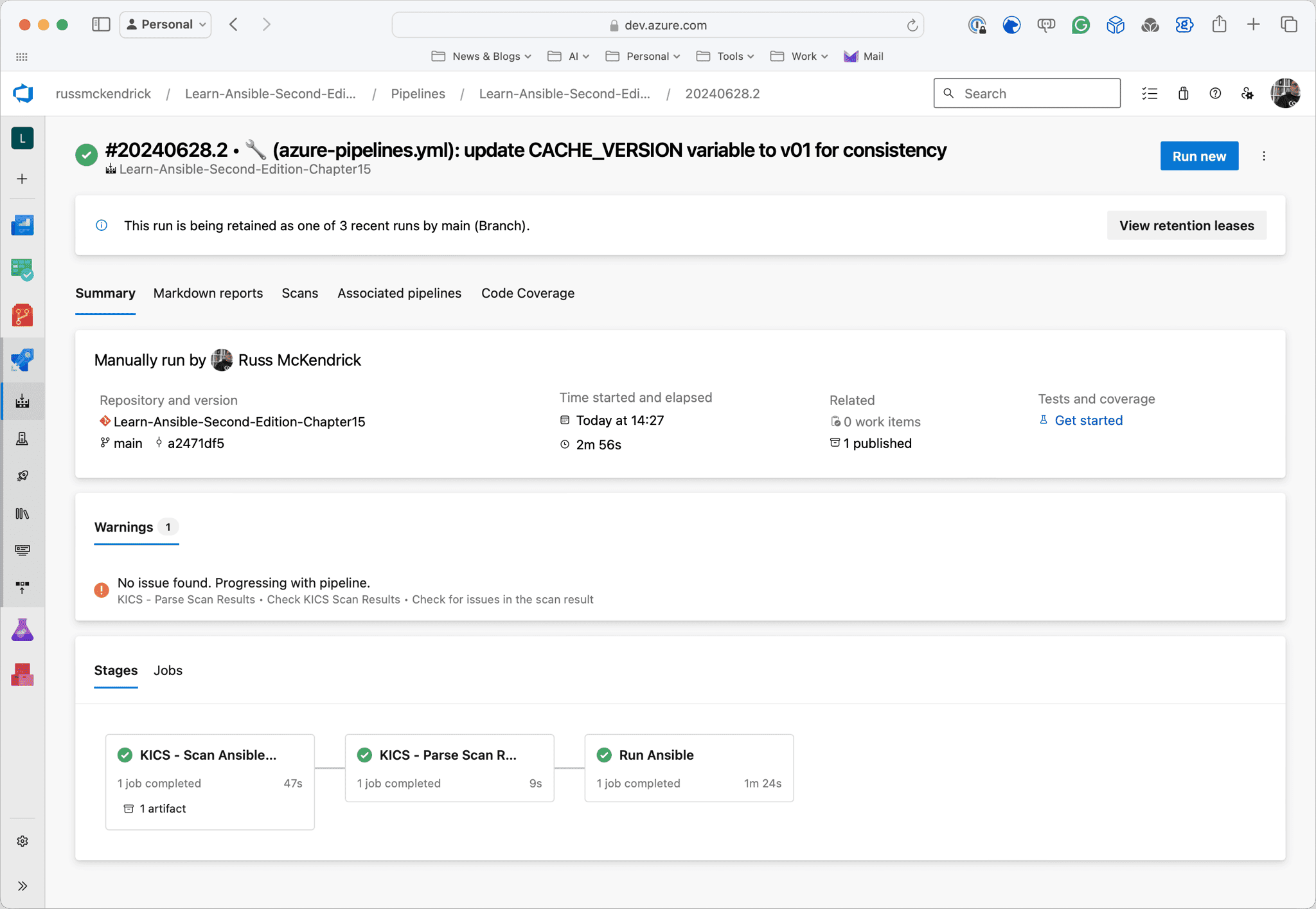
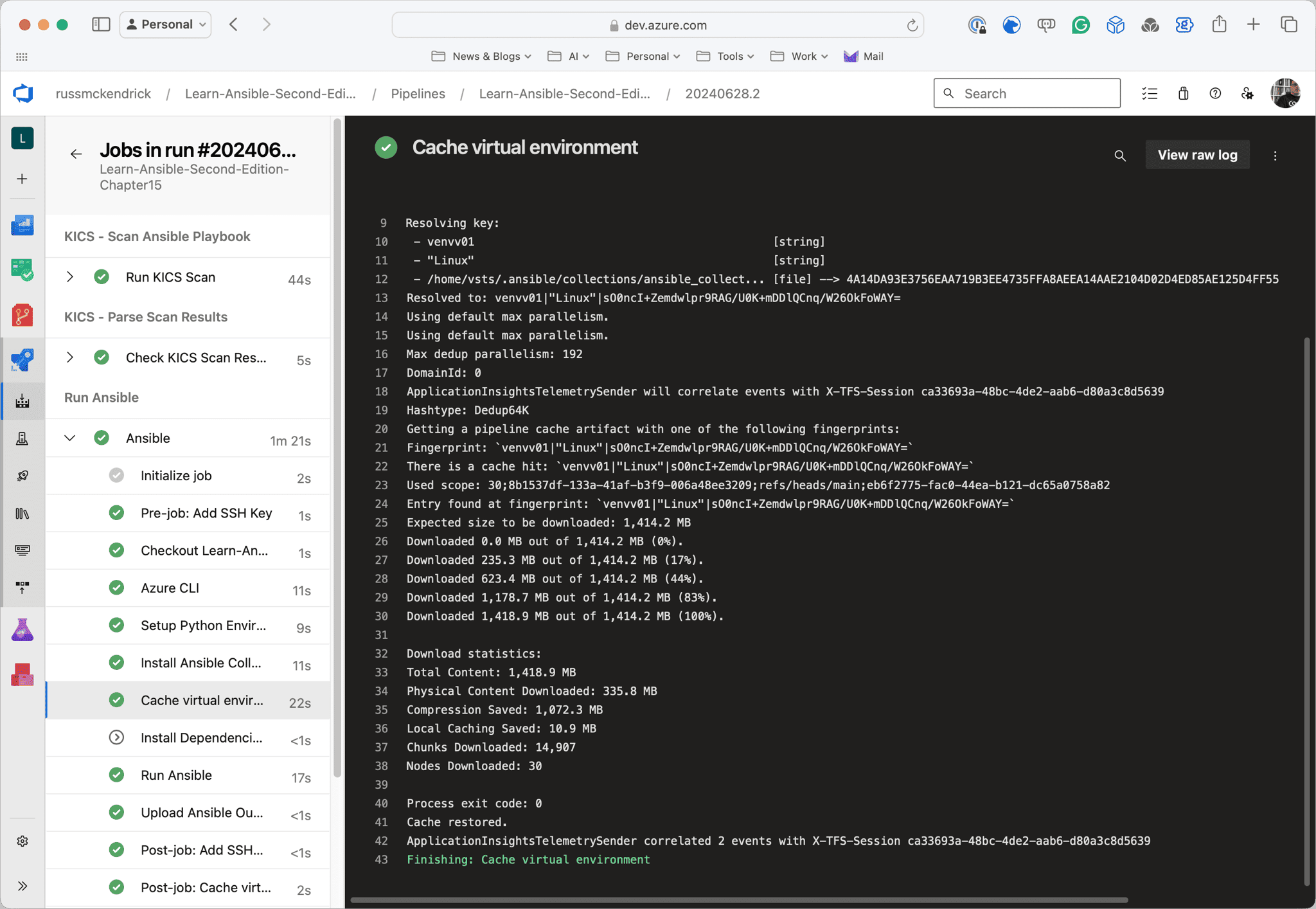
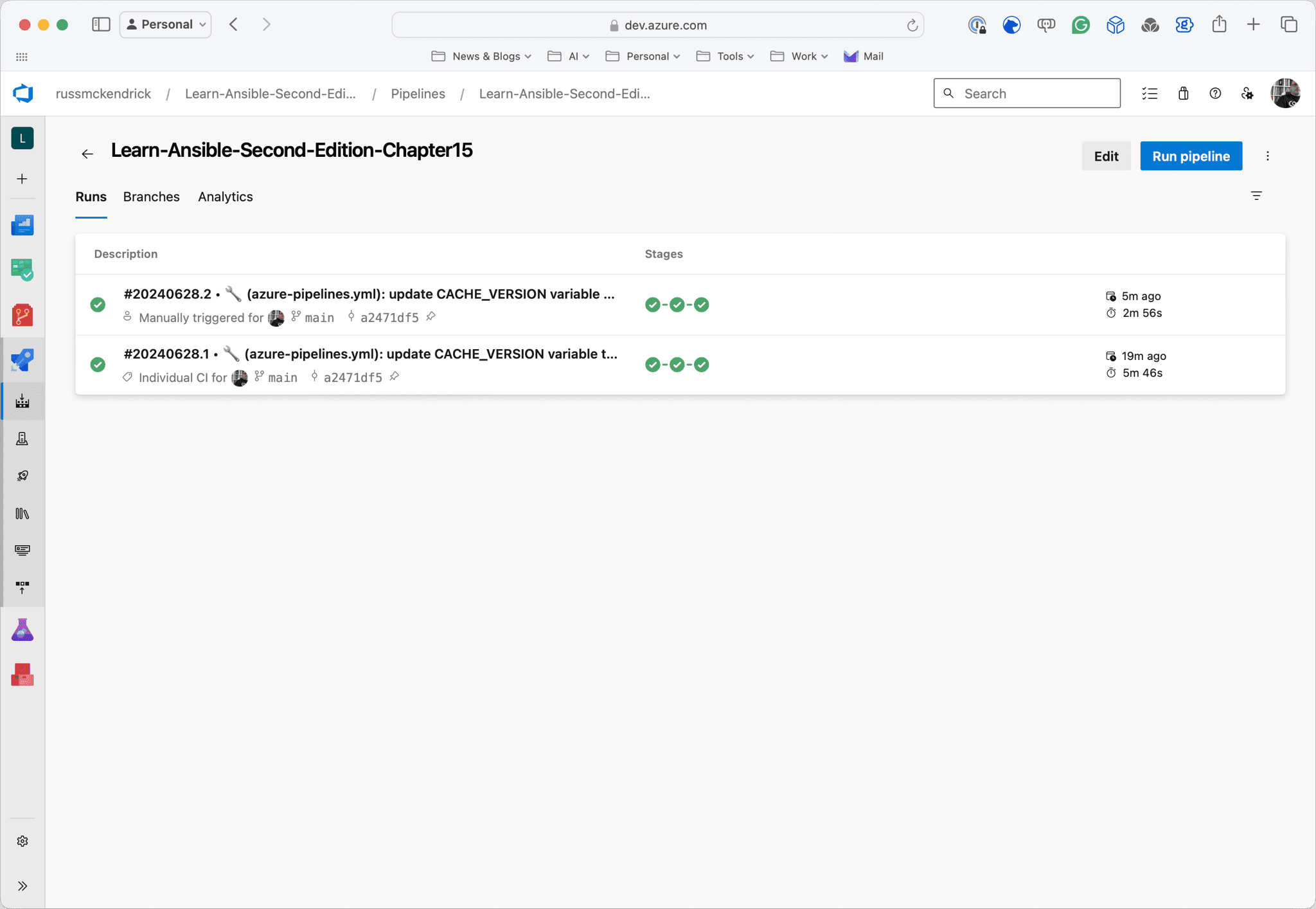
Conclusion
The introduction of caching in our Azure DevOps Ansible pipeline has significantly improved its efficiency and reduced execution time. By implementing the Cache@2 task and conditionally installing dependencies, we’ve created a pipeline that balances speed and reliability. This optimization not only saves time but also reduces network bandwidth usage, making our DevOps processes more streamlined and cost-effective.
You can find the full code below:

Further reading and links
You can buy the second edition of Learn Ansible from the link below:
Read the original blog post here:

Find out more on the Cache@2 task at:

Audio Summary
Related Posts
How to Install Ansible on a Mac: A Modern Approach
A guide to installing and managing Ansible on macOS using Conda, with tips for handling collections and dependencies.

Ansible setup with Azure on a new Mac
Learn how to set up Ansible with Azure on a new Mac, addressing common issues with cryptography and module dependencies.

Save money by pausing Microsoft Fabric Capacities with Azure Logic Apps
Learn how to automatically pause Microsoft Fabric capacities outside of working hours using Azure Logic Apps. This step-by-step guide shows you how to deploy a cost-saving automation that can significantly reduce your Fabric spend.

Comments